Introduction
One of the most powerful and popular forms of applied artificial intelligence is generative AI, which can create new content (text, images, etc) based on existing information or sources. A subset of generative AI are large language models (LLMs), which can produce or translate natural language text across various domains and tasks. Among the LLMs, GPTs stand out as the most advanced and widely used models in the world, capable of generating natural language text in response to a prompt or a question. GPTs can perform tasks such as summarizing, writing, coding, explaining and more.
GPT is an acronym for Generative Pre-trained Transformer. A transformer is a type of neural network (a fancy term given to mathematical models that learn from data) that can handle sequential data, such as words or sentences, and capture their relationships. Pre-trained means the model has been trained on a large amount of unlabelled text data before being used for a specific task.
These technologies have the potential to transform the way you support your customers. It may be automating some of the repetitive tasks that agents do every day, such as answering FAQs or drafting personalized responses, helping you draft support content, or generate summaries and reports from your customer feedback data.
But to better understand the ideas we just briefly introduced to you— and how they can realistically be applied to support today— let’s dive deeper into some of them in the following sections.
The Revolutionary LLMs

First, let’s take a closer look at LLMs, and the role they play in the AI revolution. LLMs stands for Large Language Models, which are transformer models trained on large amounts of data. GPT is one of the most famous LLMs built for text generation, but there are others as well, such as BERT, T5, and XLNet.
LLMs can be trained on a variety of data, not just text, but also code, images, and audio. This variety also allows them to generate a wide range of content, including:
- Text, such as blogs, stories, articles, essays, emails, etc.
- Images, such as photos, sketches, paintings, etc.
- Code, in most common programming languages such as python, Java, C++, etc.
- Audio, such as music, sound effects and speech.
LLMs can utilize these capabilities to perform various natural language processing tasks, such as answering questions, summarizing texts, translating languages, generating captions, etc. One of the main advantages of LLMs is that they can learn from any text data, without requiring specific labels or annotations. This means that they can leverage the vast amount of information available on the web, and adapt to different domains and contexts.
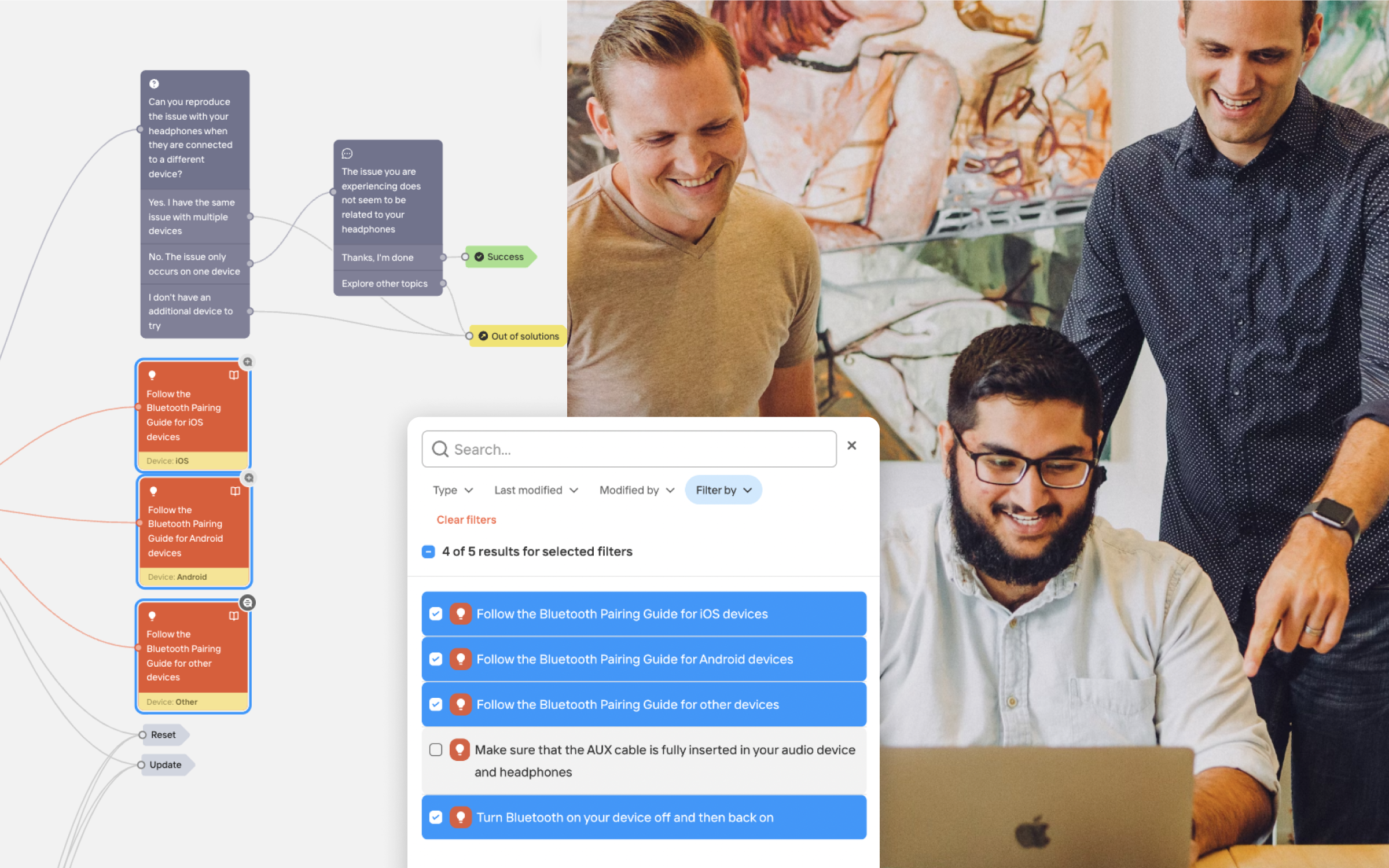
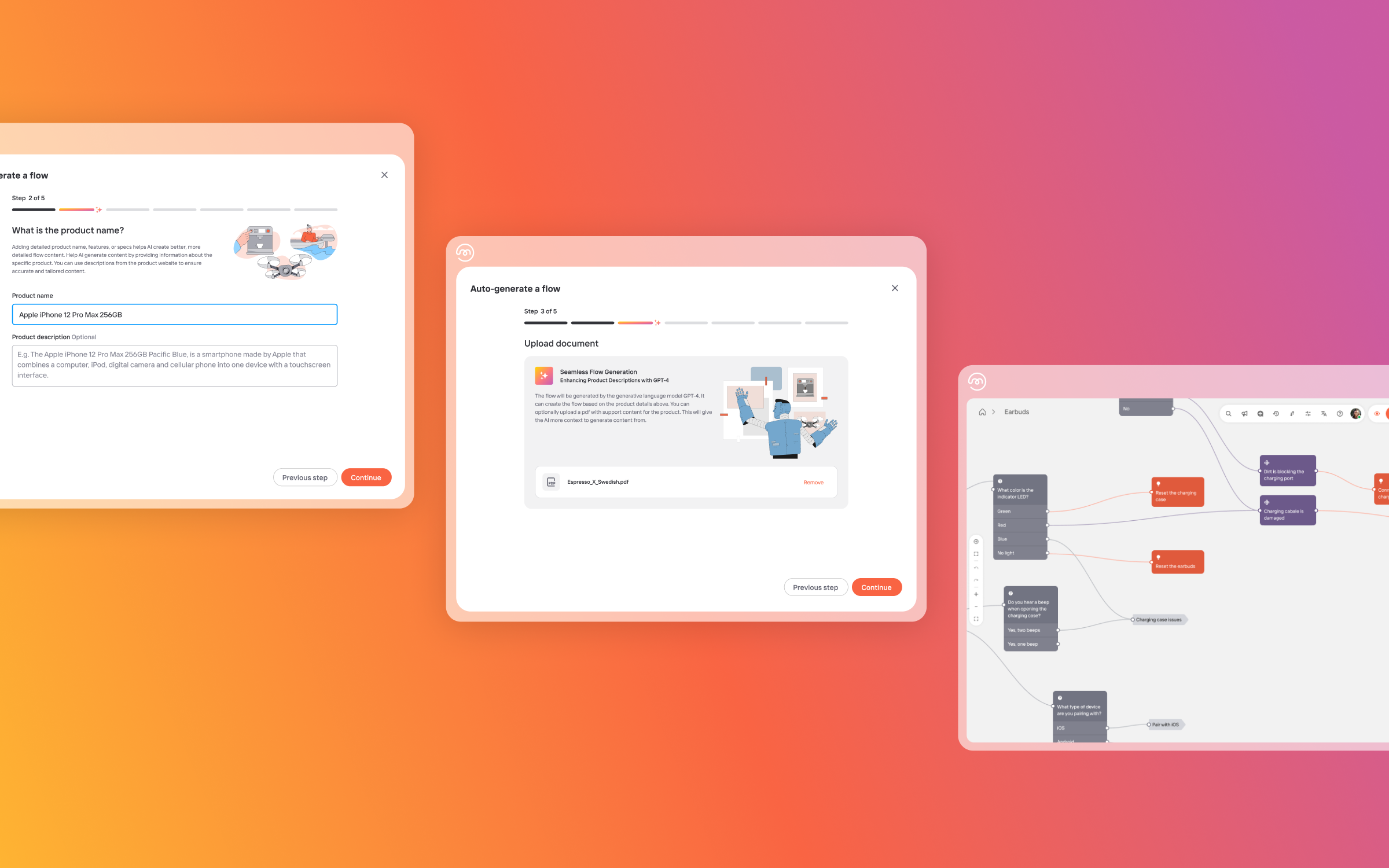
Some of the most promising use cases for hardware support are leveraging LLMs to generate support content, visual guides, or even interactive simulations helping users troubleshoot hardware issues.
For example, an LLM could be used to generate a step-by-step guide on how to disassemble a laptop and replace a faulty hard drive. Alternatively they can be tasked with creating a simulation of a computer motherboard that users can interact with to learn about the different components and how they work together.
However, LLMs also have some limitations and challenges. For example, they can be biased or inaccurate, depending on the quality and diversity of the data they are trained on. The content they create can also sometimes be hard to interpret and explain, since they rely on complex mathematical operations and hidden layers. Moreover, they can be expensive and very energy-intensive to train and run. Most people have become familiar, or at least aware, of LLMs through the rise of popular AI interface’s like ChatGPT. Let’s dive into GPT and talk more specifically about its potential applications in support.
Decoding GPT

As we already know, GPT (generative pre-trained transformers) – which is a special case of an LLM — can generate text based on a given input.
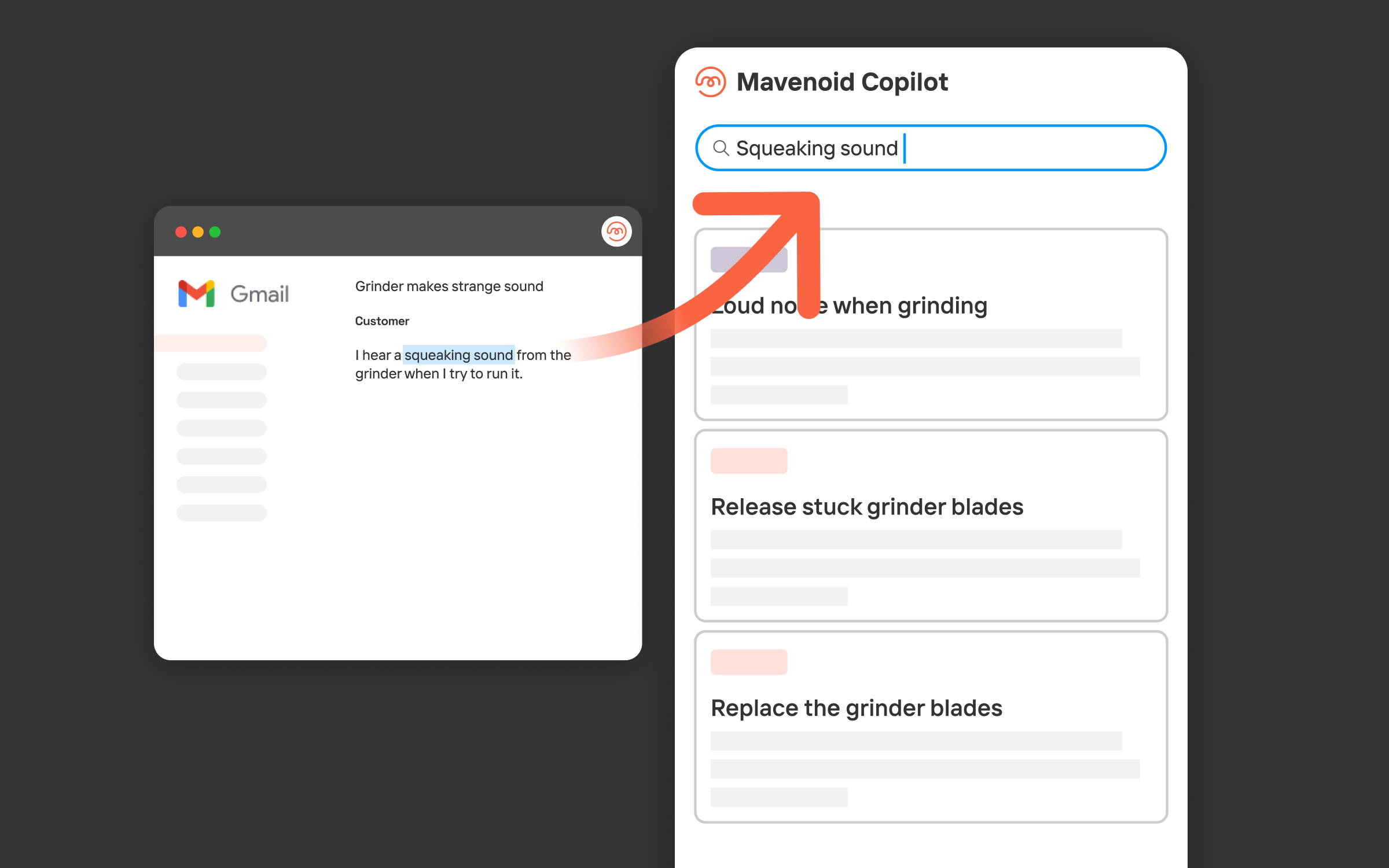
For example, if you ask ChatGPT (OpenAI’s most popular GPT interface) a question like “Why are my headphones not working?”, it can come up with some helpful suggestions like “Try adjusting the sound settings on your device” or “Make sure the headphones are connected properly”.
How does GPT do that? It’s all happening because of the massive amount of text data it has been trained on, such as books, articles, blogs, tweets, etc. It learns the rules and patterns of language from this data, and uses them to create new content. But GPT is not just a simple word predictor; it can understand the context and meaning of the input, and generate relevant and coherent answers to it.
However, it is not a magic bullet for complex use cases like hardware support. GPT has significant limitations that prevent it from being used out of the box for this purpose.
One of them is that GPT can generate text that is grammatically correct and coherent, but not necessarily accurate or relevant. For example, if you give GPT a problem like “My laptop is overheating”, it might suggest something like “Put it in the freezer” or “Spray some water on it”. This is obviously bad advice that could damage the device, but GPT ‘makes’ it sound credible, which can easily confuse the user.

GPT may also not incorporate relevant information not captured in the prompt. For example, it might suggest that a user try to fix a hardware problem by opening up their device and tinkering with the internal components, not understanding that this could void the device’s warranty or potentially damage the device, or worse, the user. With physical products, the stakes are always a bit higher; ie. if GPT instructed someone to tinker with a lawnmower’s blades, the risk of even a slight inaccuracy is very high.

Another limitation is that GPT can generate text that is inconsistent or contradictory with itself or with the given input. For example, if you give GPT a problem like “My printer is not printing”, it might suggest something like “Check the ink cartridges', and later say something like “The ink cartridges are not important”. This can confuse and frustrate the user who is looking for a clear and reliable solution.

If you are curious to explore this topic in more detail, we recommend checking out this recent article published in the New York Times. It provides some fascinating examples of hallucinating chatbots, such as ChatGPT and Google Bard, and how they have caused controversy and confusion among users and experts.
Considering the limitations, it’s important that GPT be trained and fine-tuned on specific domains and tasks to ensure its quality and reliability. It also needs to be supervised and monitored by human experts who can verify and correct its output as needed. This approach allows specialists (like Mavenoid 😉) to harness the potential of GPT, but with the oversight and focus to overcome some of its limitations.
AI and the future of hardware support
How can all of these recent AI advancements further impact hardware customer support? We already know that possibilities of using AI to automate some of the most repetitive support tasks are very promising.
Today AI is widely used (including in the Mavenoid platform) for:
- Generating responses to common customer queries
- Creating personalized product recommendations
- Generating FAQs and knowledge base articles
- Analyzing customer feedback and sentiment
- Detecting and resolving issues
And the possibilities for adding new use cases, improving customer satisfaction, and enhancing brand reputation seem endless.
However, GPTs and LLMs have their challenges and limitations. If brands use vanilla or generic transformers/models, they can end up with inaccurate or biased content, leading to poor user experiences and ineffective support.
Don’t misunderstand: GPT, LLMs and AI in general are powerful tools, of which we love being on the cutting-edge of. However, as of today, they should not be used as a 100% replacement for human expertise in support. It is important to use LLMs in conjunction with human experts to ensure that the information they generate and provide to customers is accurate and reliable.
So how does one use GPT, LLMs and AI in support, responsibly?
In the next blog posts, we will explore the following topics in more detail:
- What the advances of GPT, Generative AI and LLMs mean to hardware support, and how to implement the new technology safely and efficiently?
- How does Mavenoid use AI in 2023?
- How to ensure customers default to authorized support resources for troubleshooting?
Stay tuned for updates, and let us know what other questions you hope to have answered by the Mavenoid team.
Further reading

This blog post gives a very high-level overview of what generative AI, GPTs, and LLMs are. If you want to learn more about these technologies or try them out yourself, here are some resources we can recommend:
- OpenAI Playground: a platform, where you can interact with GPT models and generate text on various topics.
- Hugging Face: a community-based platform where you can access hundreds of pre-trained LLMs for different tasks.
- Coursera: an online learning platform where you can take courses on AI, deep learning, NLP, etc.
- Honorable mention goes to AI for everyone course: a free non-technical course for understanding AI and its application in business recommended by the Mavenoid product team
- Article: Why Chatbots Are Not the Future by Amelia Wattenberger
- Article: Google "We Have No Moat, And Neither Does OpenAI" by Dylan Patel and Afzal Ahmad
.png)
.png)

.png)

.png)